
티스토리 뷰
SRD 관련 논문은 일단 https://ieeexplore.ieee.org/document/9167399 요기 있다.
A Cloud-Optimized Transport Protocol for Elastic and Scalable HPC
Amazon Web Services (AWS) took a fresh look at the network to provide consistently low latency required for supercomputing applications, while keeping the benefits of public cloud: scalability, elastic on-demand capacity, cost effectiveness, and fast adopt
ieeexplore.ieee.org
AWS re:Invent 2022 에서 AWS에서는 클라우드에 최적화된 통신 프로토콜인 SRD를 쓴다며, 자랑했다. 그간 AWS는 Gravition, Nitro 등을 바탕으로 한 Computing 환경의 수직 계열화를 이뤄왔다. TCP 방식이 안전한 전송이라는 것은 장점이나, 열악한 환경에서 통신 환경에서 시작된 프로토콜인지라 잡음엔 강하지만, 안정적인 통신 환경에서는 전송이 느리다는 단점이 있다. 이를 개선하기 위해서 사실상 RUDP(Reliable UDP)에서 크게 변경이 없어 보이는 IP기반의 프로토콜을 만들어서 쓰는데 이게 AWS에서 2018년부터 공개한 SRD이다. 살펴봐야 하겠지만, RUDP와 크게 다르기다기 보다는 IP기반에 Nitro 하드웨어 바탕의 구현인지라 좀 더 throughput 이 높다는 정도 같다. 참고로 AWS에서는 TCP의 효율도 하드웨어 기반의 구현으로 크게 향상시키기도 했다(2021년 re:Invent). 아래는 가지고 온 관련 설명.
Why AWS removed TCP from Operating System with SRD Protocol?
https://www.linkedin.com/pulse/why-aws-removed-tcp-from-operating-system-srd-protocol-singh/
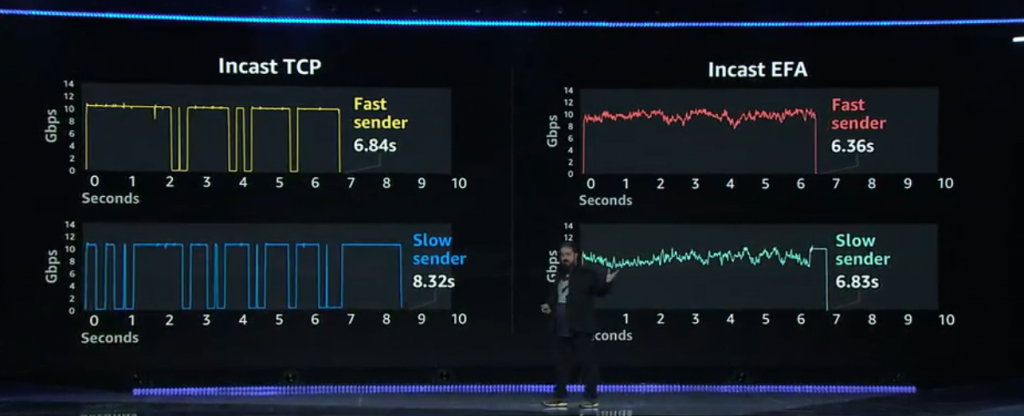
TCP is designed to deal with the internet.TCP makes communication easy it handles things like Reliability and Packet ordering and a general-purpose library and not particularly optimized for HPC. TCP is a general-purpose communication library and it’s not particulary well optimized for HPC application first TCP runs in the kernal of the OS and this makes it optimal shairng network connection amongst all the process running on your box but sharing requires overhead and this introduce latency and variablity and is too costly when micro seconds matters and latency consistnecy is paramount so an additional problem wiht TCP is that it is designed to deal with the internet and things on the internt happen in milli seconds but within our DC the packet delivery time is measured in micro second and as result tcp can introduce order of mangitude latency variabliity and this just won’t work for HPC workloads and finally TCP handles general networking condition quite well but it is not particularly well suited for HPC challanges that HPC application introduce one of this situations is a condition known as Incast, this is where a lot of servers are trying to send a lot of data to one single server effectivly overwhleming that single server Incast and it can happen during that synchronization phase that showed on below image, the surge of traffic overloads the receiver and that drops packet and inefficenct.

Fig - Incast: Many servers sending data to a single server with the same bandwidth
TCP overreacts the packet loss and it doesn’t recover nearly fast enough and that is the reason behind variability.
There is a problem of synchronization in jobs running on HPC and to solve this problem AWS build EFA and is a networking stack that’s designed for the most demanding applications and it is optimized to take advantage of the AWS DC and Nitro controller and EFA starts with a communication library that you install on your instance and this library enables your application to send message directly to Nitro controller so they completely bypass your kernel a TCP and no resource usage from your instance instead EFA hands those packets to the Nitro controller and this is where the hard work is done and they implemented transmission protocol on the Nitro controller called SRD, this a networking protocol that they designed internally using deep knowledge of how their network operates and how they perform operationally and this deep knowledge allowed them to take maximum advantage of excess throughput in the network. It also allowed them to detect packet loss or delay in microsecond retransmit several orders of magnitude faster than TCP and because all is done in Nitro controller so there is no resource consumption on the main server.
The HPC application there gets to use all those resources for their running code but they can still have a maximum network performance and scalability and EFA is designed for a very demanding networked application so of course, it deals with problems listed in Incast.
The following example shows variability in latency for existing TCP usage and compared it with new EFA and SRD and that shows its improvement on variability part where Fastest sender on TCP side becomes slower sender on Incast EFA side when we used SRD.
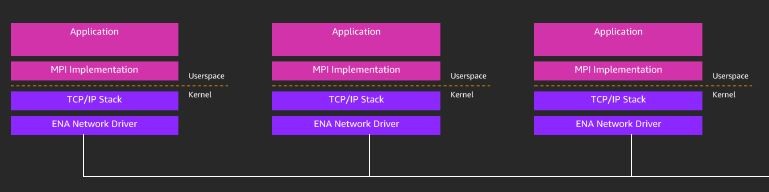
The following current HPC software stack in AWS EC2 looks like the following:
Following is the new Stack with EFA where userspace libraries are built and contributed by AWS to work with new EFA drivers:
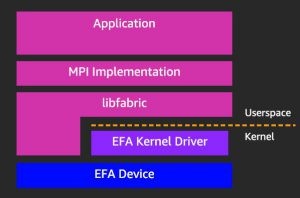
Fig- EFA Device and MPI/Libfabric interaction.
SRD quickly detects the Incast problem and adjusts in microseconds to give each stream of fair share.

Fig - SRD Setup that bypass the TCP layer and directly uses Nitro Technology
EFA is a networking adapter designed to support user-space network communication, initially offered in the Amazon EC2 environment. The first release of EFA supports datagram send/receive operations and does not support connection-oriented or read/write operations. EFA supports unreliable datagrams (UD) as well as a new unordered, scalable reliable datagram protocol (SRD). SRD provides support for reliable datagrams and more complete error handling than typical RD, but, unlike RD, it does not support ordering nor segmentation. A new queue pair type, IB_QPT_SRD, is added to expose this new queue pair type.
User verbs are supported via a dedicated userspace libfabric provider.
Kernel verbs and in-kernel services are initially not supported. EFA enabled EC2 instances to have two different devices allocated, one for ENA
(netdev) and one for EFA, the two are separate PCI devices with no in-kernel communication between them.
How to attach EFA to instances during EC instance creation:
#aws ec2 run instances count=4 region us east 1 image id ami ABCD –instance type c5n.18xlarge placement GroupName=ABCD –network-interfaces DeleteOnTermination=true,DeviceIndex=0, SubnetId
=subnet-ABCD,InterfaceType=efa –security-group-ids sg-ABCD
EFA constraints:
1. Subnet-local communication
2. Must have both an “allow all traffic within SG” Ingress and Egress rule
3. 1 EFA ENI per Instance
4. EFA ENI’s can only be added at instance launch or to a stopped instance
Scalable Reliable Datagram(SRD):
The new protocol designed for AWS’s unique data center network:
a. Network aware multipath routing.
b. Guaranteed delivery.
c. Orders of magnitude lower tail latency.
d. No ordering guarantees.
Implemented as part of our 3rd generation Nitro chip EFA exposes SRD as a reliable datagram interface
NOTE: Most of the things like EFA and SRD all are related to AWS Placement groups as only through this AWS helping you to give those benefits. Finally, In case you would like to read more than you can read more on google around the same topic.
SRD was introduced in AWS re:Invent 2018
AWS has developed its own Scalable Reliable Datagram (SRD) protocol for high-performance computing clusters as an alternative to TCP/IP
SRD was introduced in AWS re:Invent 2018
https://www.convergedigest.com/2018/11/aws-reinvent-highlights-from-day-1.html
AWS re:Invent: Highlights from Day 1
Converge! Network Digest provides comprehensive, insightful coverage of the convergence of networking technologies.
www.convergedigest.com
AWS re:Invent 2018 kicks off this week in Las Vegas. Once again the event is sold out and seat reservations are required for popular sessions. Here are the highlights from Day 1:

Introducing AWS Global Accelerator, a network service that enables organizations to seamlessly route traffic to multiple regions and improve availability and performance for their end users. AWS Global Accelerator uses AWS’s global network to direct internet traffic from end users to applications running in AWS regions. AWS says its global network is highly-available and largely congestion-free compared with the public Internet. Clients route to the optimal region based on client location, health-checks, and configured weights. No changes are needed at the client-side. AWS Global Accelerator supports both TCP and UDP protocols. It provides health checking of target endpoints and then will route traffic away from unhealthy applications or congested regions. Pricing is based on gigabytes of data transferred over the AWS network.
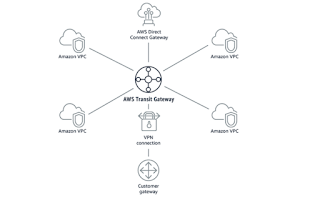
A new AWS Transit Gateway will let enterprises build a hub-and-spoke network topology on AWS infrastructure, enabling the interconnection of existing VPCs, data centers, remote offices, and remote gateways. The customer gets full control over network routing and security. Connected resources and span multiple AWS accounts, including VPCs, Active Directories, and shared services. The new AWS Transit Gateway may also be used to consolidate existing edge connectivity and route it through a single ingress/egress point. Pricing is based on a per-hour rate along with a per-GB data processing fee.

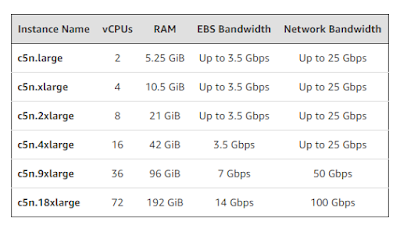
AWS introduced its first cloud instance with up to 100 Gbps of network bandwidth. Use cases are expected to include in-memory caches, data lakes, and other communication-intensive applications. AWS said its new C5n instances incorporate 4th gen custom Nitro hardware. The Elastic Network Interface (ENI) on the C5n uses up to 32 queues (in comparison to 8 on the C5 and C5d), allowing the packet processing workload to be better distributed across all available vCPUs. The ability to push more packets per second will make these instances a great fit for network appliances such as firewalls, routers, and 5G cellular infrastructure. Here are the specs:

AWS is launching its first cloud instances based on its own Arm-based AWS Graviton Processors. The new processors are the result of the acquisition of Annapurna Labs in 2015. AWS said its Graviton processors are optimized for performance and cost, making them a fit for scale-out workloads where you can share the load across a group of smaller instances. This includes containerized microservices, web servers, development environments, and caching fleets. The new A1 instances are available now in the US East (N. Virginia), US East (Ohio), US West (Oregon), and Europe (Ireland) Regions in On-Demand, Reserved Instance, Spot, Dedicated Instance, and Dedicated Host form.
In addition to processors from strategic partner Intel and its own AWS Graviton processors, AWS is offering cloud instances powered by AMD at a 10% discount.

AWS introduced Firecracker, a new virtualization technology for #containers -- think microVMs with fast startup times (125ms). The company says Firecracker uses multiple levels of isolation and protection and exposes a minimal attack surface for better security. Firecracker is expected to improve the efficiency of AWS infrastructure. It is also being released as open source. Firecracker is already powering multiple high-volume AWS services including AWS Lambda and AWS Fargate.
AWS has developed its own Scalable Reliable Datagram (SRD) protocol for high-performance computing clusters as an alternative to TCP/IP